Yuri Demchenko, TERENA <demch@terena.nl>
1998
1.1. European Multilingual Community and i18n
problems
in Internet Mail
1.2. Standardisation in i18n area (ISO, IETF, ECMA,
TERENA, Unicode Consortium)
1.3. CEN/TC304 works on European character sets and
keyboard
1.4. MAITS project
1.5. Internet Mail Consortium - Report on using
International
Characters in Internet Mail
1.6. Terena Pilot Project on Testing Multilingual
support
in MUAs
2.0. Standard on i18n and Multilingual support in Internet Mail
2.1. Terminology
2.3. IETF Policy on internationalisation and Character
Sets
2.4. ISO standards
2.5. Unicode standards
3.0. Reference
1.1. European Multilingual Community and i18n problems in Internet Mail
One of the most relevant parameter that contributes to the existing confusion in the provision of multilingual content is the large number of existing international and proprietary standards: they complicate the content creation and viewing operations, and, as a consequence, also the development and testing of internationalized software for the Internet services.
Multilingual Internet products are not just Multilingual User Interfaces that allow typing and reading messages in selected languages. Multilingual support for example in Internet Mail Systems, assumes usage of a set of mail content safe techniques and standards that include the possibility to compose, transfer and read e-mail messages containing information in different languages, character sets and encoding. In addition, they must support negotiation between MUAs and MTAs regarding the used/applied languages, character sets and encoding for each message being transferred. The Internet e-mail service is not interactive: it is a store and forward service. Therefore the multilingual negotiation here is different from the one usually used and applied in World Wide Web servers and clients model.
The essential method to verify the multilingual support by a set of MUAs and MTAs over the Internet e-mail service, consists in examining the processing of a test message composed by a set of codes representing the originator’s language and alphabet. When the test message is sent over a number of heterogeneous servers, if the multilingual support is correct, the recipient must be able to receive a readable message, identical to the one sent by the originator. The key for a correct delivery of a multilingual content in electronic mail is to ensure that the message composing software (content creation software) and the client's message reader are applying the same convention for mapping message’s codes to displayable characters (mapping bit combinations to glyphs).
The number of indigenous European languages according to CEN TC 304 is 160. The Internet literate European multilingual community uses more than 30 languages represented by many character sets with different repertoire and different encoding. A common property to all of them is the use of the character-box (or glyph-box) representation or single-byte character sets (SBCS), i.e., each character uses one displayable position. That makes a difference from the other languages used outside Europe.
Most of European languages use the Latin script, which consists of 26 base characters of the English alphabet (A through Z) in upper and lower case. Some additional characters are present in some European languages like French, Spanish or Icelandic, and many characters that are considered as characters composed from the basic ones and the diacritical marks specified in a few basic ISO standards (like ISO 6937). Fourteen diacritical marks, commonly called "accent marks" (this allows to support the nearly 200 diacritical combinations) completes the set for European Languages [1].
The repertoires of the official European languages of the members of the European Union (EU) are specified in ISO 8859-1, while the repertoires of Central and Eastern European languages using Latin alphabet are specified in ISO 8859-2. The Greek alphabet is specified in ISO 8859-7 and the Cyrillic alphabet used in Europe is specified in ISO 8859-5 [2]. The most widely used operating systems like UNIX and Microsoft Windows use their own developed character sets codes (like Windows Code Pages 1250 - 1258 or ANS) for support of the European Languages including Cyrillic languages (Russian, Ukrainian, Belorussian, Bulgarian, etc.) in CP1251 [3]. Standards de-facto for mail and news exchange as well as for WWW information in Russian and Ukrainian speaking communities are KOI8-R (RFC 1489) and KOI8-U (RFC 2319). These different character sets codes implemented in different operating systems are the main source of the incompatibility for the message content provided by MUAs running on these systems.
A study during the first half of 1997 by the Babel team gave these
counts
on a sample of 3239 home pages[4]:
| count | percentage | languages | |
| iso-8859-2 | 1 | 0.031% | Czech |
| iso-8859-5 | 2 | 0.062% | Russian |
| macintosh | 3 | 0.093% | 1 German, 1 French, 1 Italian |
| windows-850 | 4 | 0.12% | 1 French, 2 German |
| windows-1251 | 6 | 0.19% | Russian |
| windows-1250 | 10 | 0.31% | Czech |
| euc-jp | 12 | 0.37% | Japanese |
| iso-2022-jp | 38 | 1.2% | Japanese |
| shift-jis | 51 | 1.6% | Japanese |
| windows-1252 (include iso-8859-1) | 3112 | 96% | 4 Malay, 9 Danish, 14 Finnish, 19 Norwegian, 20 Dutch, 21 Portugese, 30 Italian, 35 Swedish, 38 Spanish, 57 French, 143 German, 2722 English |
Note. Counts based on automatic analysis of page contents, not on actual "charset" labels, sinceMost of users without technical IT background treat all problems with ML support in SW and MUAs as problem of support given language. But really problems consist of splits support of given language in OS and correct MUA configuring that in its turn need that MUA understand language/charset information. But mainly it’s a problem with character sets (charsets) and font in OS.
they are still too often missing or incorrect.
1.2. Standardisation in i18n area (ISO, IETF, ECMA, TERENA, Unicode Consortium)
Importance of the support for internationalization (i18n) in all Internet services especially in WWW and e-mail is widely recognized by many international forums. Recently, the strategy for support of multilinguality in all Internet services was developed and adopted by IAB and invited experts, and the result was published as an Informational RFC (RFC 2130). The basic architectural model and the basic technologies are also adopted by many organizations: however the applications used over the Internet do not yet support the proposed models and services at satisfactory level. This is why the internationalization problems are still a major discussion topic in many working groups and Technical Committees , like ISO JTC 1 TC 22 WG 20, TC2, the TERENA WG-i18n [5] and WG-MSG [6], CEN/ISSS [7] and CEN/TC304 [8], European Electronic Messaging Association[9]. A special project that addresses the implementation of internationalization standards in e-mail applications and the best of practice was undertaken by the IMC (Internet Mail Consortium) [10].
Today, the basic standardization work for support of multilinguality in e-mail applications is fairly well established: The MIME (Multipurpose Internet Mail Extensions) set of standards gives clear specifications in order to use any language into message body part and in various header fields without any danger that the underlying e-mail network infrastructure will damage the content. The main information provided in the header field that prevents the damage in the transport is the information about the coded character set used and the transfer encoding scheme like Base64, QP (see RFC 2045 - RFC 2049).
However, in practice e-mail user agents (MUAs) provide different levels of support of the multilinguality and sometimes even different treatment/processing of using MIME content-type tags in Header fields and in different parts of message body. There is also no standard scheme for assessment of the functionality and the level of compliance to the existing standards and recommendations. As a consequence, a common testing methodology (a Multilingual MUA benchmark) was not yet developed and is not yet available.
Usually, the multilingual operation of an MUA is tested by developers in a very simple-minded way, e.g. only the most simple operations are evaluated like: type, edit, send, receive/view, reply and forward of messages. From the user point of view, very important operations which are usually performed when a user is working in multilingual environment remain untested. Typical operations that are missing in manufactures’ testing of the MUA software are:
If this context is considered, many of the user-friendly products offering rich and complex facilities appear to cause more troubles than simple ones. Users of such products usually need much more instructions and recommendations on how to setup their local/national language support and how to use it in a simple message. The problem becomes even more evident when the local community uses more than one character set or encoding for their languages (or alphabets). We should also remember that many western-European languages, which are usually considered encodable without problems in US-ASCII, require special support for some of their "special characters" in order to be spelled correctly.message composition using clipboard operation (cut, paste, encrypt, translate, etc.) use of languages and character sets in the Address and Subject fields that are different from the Message body part message and document attachment.
1.3. CEN/TC304 works on European character sets and keyboard
ISSS (Information Society Standardization System) [7] has been created by CEN to include all the relevant European Information Society standardization activities under a single umbrella. CEN established a number of Technical Committees in the field of Information and Communications Technology (ICT), producing European Standards and pre-standards. CEN/TC 304 ICT - European Localisation Requirements deals with i18n/l10n and Cultural requirements for European Multilingual community [8].
CEN/TC 304 undertaken special project on IT standards and European Cultural requirements which splits its work on the following problems:
1. European keyboards. The deliverable is a CEN report giving guidance on the application of international keyboard standards in Europe. It will map how national bodies are using international keyboard standards, what national standards there are, give guidance to common approaches. Special attention shall be given to the Euro Sign on keyboards.
2. Guide on the use of character sets. The deliverable is a CWA or CEN specifications in Europe. This guide is to be useful for procurement purposes and non- technical people. It shall use existing guides which are almost exclusively based upon the 7-bit and 8-bit code structure, bring this information up to date and add material on the new 10646/Unicode structure.
3. Character conversion model (Character repertoire and coding transformation, part 1 - General model for character transformations) The deliverable is an EN (European standard) that defines a general model for graphic character transformations, with respect to repertoires and their coded representation. The model may also define the handling of a limited set of control functions and define rules for the registration of existing transformation methodologies.
4. Character conversion - fallback rules (Character repertoire and coding transformations, part 2 - European conversion and fallback rules.) The deliverable is an EN defining specific European fallback rules for use when transforming into ISO 646- IRV from the MES (the European subset of 10646 in ENV 1973).
5. Character conversion method - ISO/IEC 2022 (Character repertoire and coding transformations, part 3 - Transformation method based on ISO/IEC 2022) The deliverable is an EN describing a methodology used to transform coded character strings in a way compatible to the General character conversion model (see above) using the provisions of several International Standards, mainly these of ISO/IEC 2022.
6. Character conversion method - based on UTF mnemonic (Character repertoire and coding transformations, part 4 - Conversion method UTF-mnemonic) The deliverable is an EN specifying a coded character set conversion scheme UTF- mnemonic. This scheme has originally been employed and defined in the Internet environment, and the current compatible Internet specification RGC-1345. The scheme is defined to represent all of the 32-bit standard ISO/IEC 10646 without loss of information in many other coded character sets, via a symbolic character name introducer and mnemonic symbolic character names.
7. European matching rules (scoping) The deliverable is a study report, defining the background scope of further work on European rules for browsing and searching. The objective of this project is to investigate the European needs and problems with searching and browsing, in relation to character sets, transliteration, matching and ordering rules and other cultural specific elements. The needs for a European set of requirements in this area at the present state of technology will be investigated.
8. European Specific requirements (A European Project on the Information Infrastructure: European Culturally Specific requirements). The deliverable is a CEN Report or a CEN Workshop Agreement containing an initial check list of European Specific requirements. It shall provide a framework of requirements for use in the definition of middleware and service specifications. It shall also refer to existing descriptions of middleware and service properties to be used in a European environment. Identify in addition to the requirements, a program of work needed to realize those requirements where they might usefully be subject to standardization.
9. Scope for European Regulatory requirements. The deliverable is a CEN Report or a CEN Workshop Agreement providing the scope for further work on the Political, Regulatory and Legal requirements for systems and services within the Information Society in Europe. This further work is aimed at supporting other standardization work and those responsible for planning, development and operation of systems and services in Europe and especially those involved in crossborder information flows.
10. European ordering rules (EES) (Multilingual string ordering rules for the Extended European Subset of ISO/IEC 10646) The deliverable is a CEN Work Shop agreement or an ENV specifying multilingual Extended Subset Ordering rules for Europe. This project team shall work closely with the Project Team being set up for ordering the MES, but the alphabet to be covered is larger.
The MAITS Project [12] has identified several needs for the user in a global multilingual work environment.
MAITS defines four levels of Transparent Language Processing (TLP):use the service in a language and script of their choice, both for input and output, work in their own national or cultural environment, and switch between different languages and scripts.
0. Codeset Conversion
At this level, the accessed data is converted to the character sets usable by the client platform so that they can be visible to the user.
1. Transliteration and Cultural String Formatting
At Level-1, language-sensitive transliteration is added to allow access to data encoded in different scripts (such as accessing Greek or Cyrillic from a French workstation). Correct cultural formatting of date/time, numeric, and currency fields occur here.
2. Translation Memory
Level-2 TLP adds the ability for an application to query a stored pool of context-sensitive translated words and phrases to build up language specific keywords, attributes fields, and basic error messages.
3. Machine Translation
Level-3 TLP includes parallel machine translation of body text for first-cut approximations of textual content for the end-user. User Community MAITS intends to create a low-level API (Application Programming Interface) to enhance existing standards for globalization.
Some project's objectives are intended for enhancement of multilingual features of mail related standards and products (X.400, exmh). Project proposed different scenarios of implementation of Multilingual features/support in telematics services and products according to listed TLP layers.
The core technology intended to be integrated into MAITS model exists, but in different, non-standardized forms. Transliteration is a design feature of the "C3" conversion engine. Codeset conversion is already an integral part of Alis Technologies and Sybase products. And machine translation packages exists for many language pairs and many platform environments. MAITS aims to integrate these many disparate technologies in an integrated, unified whole, to enable the standards bodies that influence the ultimate content and format of telematic services for global multilingual distributed environments.
MAITS proposes typical scenarios for implementation different levels of TLP model. Project realisation is undertaken by MAITS Consortium:
Some of the most important problems of internationalization in Internet mail are covered in this report. They
include:
| 1. Explicit charset parameter | All body parts that include human-readable text and are created with a Content-type header should include an explicit charset parameter, even if the charset is US-ASCII. |
| 2. Sending UTF-8 | All mail-creating programs created or revised after January 1, 1999, must be able to create mail using the UTF-8 charset. Another way to say this is that any program created or revised after January 1, 1999, that cannot create mail using the UTF-8 charset should be considered deficient and lacking in standard internationalization capabilities. |
| 3. Displaying UTF-8 | All mail-displaying programs created or revised after January 1, 1999, must be able to display mail that uses the UTF-8 charset. Another way to say this is that any program created or revised after January 1, 1999, that cannot display mail using the UTF-8 charset should be considered deficient and lacking in standard internationalization capabilities. Of course, all mail-displaying programs should try to meet this requirement as early as possible. |
| 4. Choosing charsets on creation | All mail-creating programs that are controlled by humans should allow the sender to choose the charset used to create a message. These programs should also give advice to the user about the different charsets, such as about the likelihood that the recipient will be able to display a particular charset. |
| 5. Specifying languages | All body parts that are created with a Content-type header that include human-readable text should also include a Content-language header. This practice makes it more likely that programs that process messages where different languages would process differently will process them correctly. |
| 6. Multi-language text | All plain text body parts that use UTF-8 and have more than one language should use Unicode Language Tags in addition to a Content-language header. However, Unicode Language Tags should only be used with plain text body parts that have more than one language; they should not be used with body parts that have a single language, nor should they be used with structured text body parts such as those coded with HTML. |
| 7. Non-ASCII headers | All mail-creating programs should allow users to use non-ASCII characters in message headers, as described in RFC 2047 and RFC 2231. Headers that conform to these two RFCs are not known to harm any mail-displaying process that does not conform to the RFCs. The charsets used in these headers should be chosen using the similar methods to choosing charsets for the bodies of the messages to which they are attached. |
| 8. Handling all common charsets | All mail-creating and mail-displaying programs created or revised after January 1, 1999, should be able to handle many common charsets in addition to UTF-8. Another way to say this is that any mail-creating and mail-displaying program created or revised after January 1, 1999, that cannot handle a wide variety of common charsets should be considered deficient and lacking in standard internationalization capabilities. |
| 9. MTAs and 8-bit content | All SMTP servers should support the 8BITMIME extension, as described in RFC 1652. |
1.6. Terena Pilot Project on Testing Multilingual support in MUAs [13]
The Pilot Project to evaluate the most popular Multilingual MUAs was launched at the beginning of 1998 by TERENA WG-MSG and WG-i18n. The project major goal is to provide (within the TERENA technical program) its users' community with consistent information and practical recommendations about the level and quality of the multilingual support in these widely used MUAs. The project officially started in April 1998 and have delivered main results by September 1998. The project specified, by mean of evaluation tests, the properties of each particular MUA and provided necessary recommendations and instructions for a correct configuration of particular MUAs.
The tests were performed on a number of MUAs with the intention to determine their behavior when configured to work with different national character sets. The list of mail client to be tested was derived from TERENA MUAs usage statistics based on analysis of more than 3000 messages from TERENA Mail archives collected during the period August 1997 - March 1998. The list was approved by the TERENA Working Groups for Internationalization of the network services (WG-I18N) and the TERENA Working Group for Mail and Messaging (WG-MSG).
The project made evaluate the MUAs in general but some evaluation of the local e-mail encoding practice was also provided for some special cases with large users community. This applies for countries that use some special coded character sets for their languages e.g. in Russia, Ukraine and Belarus (for DOS, Windows, UNIX, Macintosh, etc.) and in some Central European Countries like Poland, Slovenia, Czech Republic, Hungary, etc.
The project objectives can be described as:
Main results of the projectDevelop benchmarking methodology for Multilingual MUAs, and specify templates for collecting the results in a coherent way. Design a set of composite multilingual test messages to test multiple languages support in MUAs. Configure each MUA for all supported national character sets and send the test messages to other MUAs and to themselves. Compile the results, analyzing how the MUA composes, sends, receives and displays the test messages. Prepare recommendations for users and define instructions for correct setup and operation of some popular multilingual MUAs in order to avoid incorrect delivery ("distortion") of the sent messages.
1. Main problems in multilingual MUAs support have been discovered
2. Multilingual test messages set created
3. Evaluation scheme for the forthcoming ML MUAs proposed
4. A number of popular in TERENA community MUAs have been tested
In details these results are described in Project's final report [14].
Project has two homes:
2.0. Standard on i18n and Multilingual support
in Internet Mail
Character set technology in ISO, IETF (RFC), etc.
2.1. Terminology
2.2. RFC 822 mail format and MIME content type tags
in
Internet Mail
2.2.1. Syntax of electronic messages format according
to RFC 822
2.2.2. MIME format of messages (Using MIME in
Internet
Mail) RFC 2045-RFC 2049
2.3. IETF Policy on internationalisation and
Character
Sets
2.3.1. RFC 2277 IETF Policy on Character
Sets and Languages
2.3.2. Requirement for language tagging
2.3.3. Locale
2.3.4. Recommendation of IAB Workshop on character
sets technology (RFC 2130)
2.4. ISO standards
2.4.1. ISO 2022 Character Set Concept and Terminology
2.4.2. ISO 8859-x Character Sets
2.4.3. ISO Standards on APIs i18n and Formal
Description
of Cultural Contents
2.5. Unicode standards
This section discusses standards and other recommendations in area of character set technologies and internationalisation in Internet and particularly in Internet Mail.
Terminology in i18n and character sets technology is discussed and documented in many international standards and documents. But in many cases some terms are defined and treated in different ways in different standards. For Internet community as really international it is recommended some common approach and view for definition of main terms. Two such attempts are well known: first is IAB Workshop on character set technology described in RFC 2130 and IMC report on internationalisation in Internet Mail) [11].
Refer to the latest RFCs, ISO standards and IMC report we can list the following definitions
A character is the smallest component of written language that has semantic value. A character has a single abstract meaning and/or shape, but not a specific shape.
A glyph is the specific shape that a character can have when it is rendered or displayed. A single glyph may correspond to a single character, or it may correspond to many characters; for example, the same glyph is used to represent the Latin capital letter "P" and the Greek capital letter "Rho". Similarly, a single character may correspond to multiple glyphs due to font, formatting style, national differences, and other reasons.
A character set (more precisely called a "coded character set" or "CCS") is a mapping from a set of abstract characters to a set of integers. Examples of coded character sets include ISO 10646, US-ASCII, and the ISO 8859 series.
A character encoding scheme or "CES" is a mapping from one or more coded character sets to a set of octets. Some CESs are associated with a single CCS; for example, UTF-8 applies only to ISO 10646. Other CESs, such as ISO 2022, are associated with many CCSs.
Charset is a method of mapping a sequence of octets to a sequence of abstract characters. A charset is, in effect, a combination of one or more CCS with a CES. Charset names are registered by the IANA according to procedures documented in RFC 2278 that also lists requirements for characteristics, naming, usage and implementation, functionality, publication to the charset to be registered.
Another useful definitions to know come from recent ISO standards on localisation and cultural convention are listed below.
Cultural convention: A data item for computer use that may vary dependent on language, territory, or other cultural circumstances.
FDCC-set: A Set of Formal Definitions of Cultural Conventions. The definition of the subset of a user's information technology environment that depends on language and cultural conventions. Note: the FDCC-set is a superset of the "locale" term in C and POSIX.
Charmap: A definition of a mapping between symbolic character names and the encoding for a coded character set"
Repertoiremap: A definition of a mapping between symbolic character names and characters for the repertoire of characters used in a FDCC-set, further described in clause 6.
Collation: The logical ordering of strings according to defined precedence rules.
Transliteration - transformation of characters of one language into characters of another language.
NOTE. Transliteration of the same script may be different, for example, a Serbian text and a Russian text, both written in the Cyrillic script, may have different transcription rules for the language Danish. The transformation may be between different scripts, as in the previous example, or within the same script, for example Swedish to Danish where ömay become ø, and ä become æ.
Transcription - transformation of sounds of one language into characters of another language.
NOTE. Transcription has the same characteristics as noted for transliteration.
Locale. The POSIX standard defines a concept called a "locale", which includes a lot of information about collating order for sorting, date format, currency format and so on.
Note that language and character set information will often be present as parts of a locale tag (such as no_NO.iso-8859-1; the language is before the underscore and the character set is after the dot); care must be taken to define precisely which specification of character set and language applies to any one text item.
A number of terms are introduced in ISO 2022 to describe complicated scheme of forming single byte and multibyte (nested) character encoding scheme.
Control character: A control function the coded representation of which consists of a single bit combination.
Graphic character: A character, other than a control function, that has a visual representation normally handwritten, printed or displayed, and that has a coded representation consisting of one or more bit combinations.
Repertoire: A specified set of characters that are each represented by one or more bit combinations of a coded character set.
2.2. RFC 822 mail format and MIME content type tags in Internet Mail
2.2.1. Syntax of electronic messages format according to RFC 822 [16]
Usually, format of E-mail messages is explained for user in very simple manner as having a number of header fields To:, From:, Subject:, etc. and message body. Purpose of current report and standard overview is to give users and internationalisation (support) team necessary knowledge how to handle problems and evaluate multilingual features of given MUA when working or configuring it for multilingual environment. They should understand not only what they see on the screen/display via MUA’s GUI but understand how to identify ML problems and analyze message source.
MESSAGE SYNTAX
According to the augmented BNF (notational convention) of RFC 822 Due to an artifact of the notational conventions, the syntax indicates that, when present, some fields, must be in a particular order. Header fields are NOT required to occur in any particular order, except that the message body must occur AFTER the headers. It is recommended that, if present, headers be sent in the order "Return-Path", "Received", "Date", "From", "Subject", "Sender", "To", "cc", etc. This specification permits multiple occurrences of most fields.
The following syntax for the bodies of various fields should be
thought
of as describing each field body as a single long string (or line).
message = fields *( CRLF *text ) ; Everything after
When message is forwarded fields of original message are
prefixed by Resent-
but their semantics is remain the same as original message.
; first null line
; is message body
fields = dates ; Creation time,
source ; author id & one
1*destination ; address required
*optional-field ; others optional
source = [ trace ] ; net traversals
originator ; original mail
[ resent ] ; forwarded
trace = return ; path to sender
1*received ; receipt tags
return = "Return-path" ":" route-addr ; return address
received = "Received" ":" ; one per relay
["from" domain] ; sending host
["by" domain] ; receiving host
["via" atom] ; physical path
*("with" atom) ; link/mail protocol
["id" msg-id] ; receiver msg id
["for" addr-spec] ; initial form
";" date-time ; time received
originator = authentic ; authenticated addr
[ "Reply-To" ":" 1#address] )
authentic = "From" ":" mailbox ; Single author
/ ( "Sender" ":" mailbox ; Actual submittor
"From" ":" 1#mailbox) ; Multiple authors
; or not sender
resent = resent-authentic
[ "Resent-Reply-To" ":" 1#address] )
resent-authentic =
= "Resent-From" ":" mailbox
/ ( "Resent-Sender" ":" mailbox
"Resent-From" ":" 1#mailbox )
dates = orig-date ; Original
[ resent-date ] ; Forwarded
orig-date = "Date" ":" date-time
resent-date = "Resent-Date" ":" date-time
destination = "To" ":" 1#address ; Primary
/ "Resent-To" ":" 1#address
/ "cc" ":" 1#address ; Secondary
/ "Resent-cc" ":" 1#address
/ "bcc" ":" #address ; Blind carbon
/ "Resent-bcc" ":" #address
optional-field =
/ "Message-ID" ":" msg-id
/ "Resent-Message-ID" ":" msg-id
/ "In-Reply-To" ":" *(phrase / msg-id)
/ "References" ":" *(phrase / msg-id)
/ "Keywords" ":" #phrase
/ "Subject" ":" *text
/ "Comments" ":" *text
/ "Encrypted" ":" 1#2word
/ extension-field ; To be defined
/ user-defined-field ; May be pre-empted
msg-id = "<" addr-spec ">" ; Unique message id
extension-field =
<Any field which is defined in a document
published as a formal extension to this
specification; none will have names beginning
with the string "X-">
user-defined-field =
<Any field which has not been defined
in this specification or published as an
extension to this specification; names for
such fields must be unique and may be
pre-empted by published extensions>
Examples of Headers
1. Minimum required
Note that the "Bcc" field may be empty, while the "To" fieldDate: 26 Aug 76 1429 EDT Date: 26 Aug 76 1429 EDT
From: Jones@Registry.Org or From: Jones@Registry.Org
Bcc: To: Smith@Registry.Org
is required to have at least one address.
2. Using some of the additional fields
3. About as complex as you're going to getDate: 26 Aug 76 1430 EDT
From: George Jones <Group@Host>
Sender: Secy@SHOST
To: "Al Neuman"@Mad-Host,
Sam.Irving@Other-Host
Message-ID: < some.string@SHOST>
2.2.2. MIME format of messages (Using MIME in Internet Mail) RFC 2045-RFC 2049Date : 27 Aug 76 0932 PDT
From : Ken Davis <KDavis@This-Host.This-net>
Subject : Re: The Syntax in the RFC
Sender : KSecy@Other-Host
Reply-To : Sam.Irving@Reg.Organization
To : George Jones <Group@Some-Reg.An-Org>,
Al.Neuman@MAD.Publisher
cc : Important folk:
Tom Softwood <Balsa@Tree.Root>,
"Sam Irving"@Other-Host;,
Standard Distribution:
/main/davis/people/standard@Other-Host,
"<Jones>standard.dist.3"@Tops-20-Host>;
Comment : Sam is away on business. He asked me to handle
his mail for him. He'll be able to provide a
more accurate explanation when he returns
next week.
In-Reply-To: <some.string@DBM.Group>, George's message
X-Special-action: This is a sample of user-defined field-
names. There could also be a field-name
"Special-action", but its name might later be
preempted
Message-ID: < 4231.629.XYzi-What@Other-Host>
It is assumed that MTA/SMTP transport allows/support only 7 bit characters in mail messages because of most mail relays and gateways are designed according to RFC 821 allowing only 7 mail transfer [15].
MIME (Multipurpose Internet Mail Extension) allow 8 bit mail content and propose methods (Transfer Syntax) for 8 bit transport over 7 bit mail relays.
RFC 822, defines a message representation protocol specifying considerable details about US-ASCII message headers, and leaves the message content, or message body, as flat US-ASCII text. Wider use of Internet Mail according to RFC 822 format unleashed its limitation for international and wide user community. The set of RFC 2045-2049, collectively called the Multipurpose Internet Mail Extensions, or MIME, redefines the format of messages to allow for
(1) textual message bodies in character sets other than US-ASCII,
(2) an extensible set of different formats for non-textual message bodies,
(3) multi-part message bodies, and
(4) textual header information in character sets other than US-ASCII.
The initial document RFC 2045 [17] specifies the
various headers used to describe the structure of MIME messages. The
second
document, RFC 2046 [18], defines the general
structure
of the MIME media typing system and defines an initial set of media
types.
The third document, RFC 2047 [19], describes
extensions
to RFC 822 to allow non-US-ASCII text data in Internet mail header
fields.
The fourth document, RFC 2048 [20], specifies
various
IANA registration procedures for MIME-related facilities. The fifth and
final document RFC 2049 [21] describes MIME
conformance
criteria as well as providing some illustrative examples of MIME
message
formats.
RFC 822 was intended to specify a format for text messages. Even in the case of text, however, RFC 822 is inadequate for the needs of mail users whose languages require the use of character sets richer than US-ASCII. RFC 822 does not specify mechanisms for mail containing audio, video, Asian language text, or even text in most European languages, additional specifications.
RFC 2045 describes several mechanisms that combine to solve most of these problems without introducing any serious incompatibilities with the existing world of RFC 822 mail. In particular, it describes:
(1) A MIME-Version header field, which uses a version number to declare a message to be conformant with MIME.
(2) A Content-Type header field which can be used to specify the media type and subtype of data in the body of a message and to fully specify the native representation (canonical form) of such data.
(3) A Content-Transfer-Encoding header field, which can be used to specify both the encoding transformation that was applied to the body and the domain of the result. Encoding transformations other than the identity transformation are usually applied to data in order to allow it to pass through mail transport mechanisms which may have data or character set limitations.
(4) Two additional header fields that can be used to further describe the data in a body, the Content-ID header and Content-Description header fields.
MIME defines a number of new RFC 822 header fields that are used to describe the content of a MIME entity. They can occur as parts of a regular RFC 822 message header or in a MIME body part header within a multipart construct.
Messages composed in accordance with this document MUST include MIME-Version Header Field, with the following verbatim text:
The purpose of the Content-Type field is to describe the data contained in the body fully enough that the receiving user agent can pick an appropriate agent or mechanism to present the data to the user, or otherwise deal with the data in an appropriate manner. The value in this field is called a media type. In the Augmented BNF notation of RFC 822, a Content-Type header field has the following syntax:MIME-Version: 1.0
Subtype specification is MANDATORY -- it may not be omitted from a Content-Type header field. As such, there are no default subtypes. The type, subtype, and parameter names are not case sensitive.content := "Content-Type" ":" type "/" subtype
*(";" parameter)
; Matching of media type and subtype
; is ALWAYS case-insensitive.
type := discrete-type / composite-type
discrete-type := "text" / "image" / "audio" / "video" /
"application" / extension-token
subtype := extension-token / iana-token
Media types use in MIME Content-Type should be registered via standard IANA procedure or establish bilaterally between two cooperating agents. In this case private values start with "X-".
Content-Type Defaults are
Content-Transfer-Encoding Header FieldContent-type: text/plain; charset=us-ascii
Content-Transfer-Encoding Header defines a standard mechanism for encoding arbitrary (8-bit) data into a 7bit short line format. Proper labeling of unencoded material in less restrictive formats for direct use over less restrictive transports is also desirable. This document specifies that such encodings will be indicated by a new "Content-Transfer-Encoding" header field. This field has not been defined by any previous standard.
The Content-Transfer-Encoding field's value is a single token specifying the type of encoding:
Quoted-Printable Content-Transfer-Encodingencoding := "Content-Transfer-Encoding" ":" mechanism
mechanism := "7bit" / "8bit" / "binary" /
"quoted-printable" / "base64" /
ietf-token / x-token
The Quoted-Printable encoding is intended to represent data that largely consists of octets that correspond to printable characters in the US-ASCII character set. It encodes the data in such a way that the resulting octets are unlikely to be modified by mail transport. If the data being encoded are mostly US-ASCII text, the encoded form of the data remains largely recognizable by humans. A body which is entirely US-ASCII may also be encoded in Quoted-Printable to ensure the integrity of the data should the message pass through a character-translating, and/or line-wrapping gateway.
In this encoding, octets are to be represented as determined by the following rules:
The Base64 Content-Transfer-Encoding is designed to represent arbitrary sequences of octets in a form that need not be humanly readable. The encoding and decoding algorithms are simple, but the encoded data are consistently only about 33 percent larger than the unencoded data.
A 65-character subset of US-ASCII is used, enabling 6 bits to be represented per printable character. (The extra 65th character, "=", is used to signify a special processing function.)
The encoding process represents 24-bit groups of input bits as output strings of 4 encoded characters. Proceeding from left to right, a 24-bit input group is formed by concatenating 3 8bit input groups. These 24 bits are then treated as 4 concatenated 6-bit groups, each of which is translated into a single digit in the base64 alphabet. When encoding a bit stream via the base64 encoding, the bit stream must be presumed to be ordered with the most-significant-bit first. That is, the first bit in the stream will be the high-order bit in the first 8bit byte, and the eighth bit will be the low-order bit in the first 8bit byte, and so on.
Each 6-bit group is used as an index into an array of 64 printable characters. The character referenced by the index is placed in the output string. These characters, identified in Table 1, below, are selected so as to be universally representable, and the set excludes characters with particular significance to SMTP (e.g., ".", CR, LF) and to the multipart boundary delimiters defined in RFC 2046 (e.g., "-").
Table 1: The Base64 Alphabet
| Value | Encoding | Value | Encoding | Value | Encoding | Value | Encoding |
| 0 | A | 17 | R | 34 | I | 51 | z |
| 1 | B | 18 | S | 35 | j | 52 | 0 |
| 2 | C | 19 | T | 36 | k | 53 | 1 |
| 3 | D | 20 | U | 37 | l | 54 | 2 |
| 4 | E | 21 | V | 38 | m | 55 | 3 |
| 5 | F | 22 | W | 39 | n | 56 | 4 |
| 6 | G | 23 | X | 40 | o | 57 | 5 |
| 7 | H | 24 | Y | 41 | p | 58 | 6 |
| 8 | I | 25 | Z | 42 | q | 59 | 7 |
| 9 | J | 26 | a | 43 | r | 60 | 8 |
| 10 | K | 27 | b | 44 | s | 61 | 9 |
| 11 | L | 28 | c | 45 | t | 62 | + |
| 12 | M | 29 | d | 46 | u | 63 | / |
| 13 | N | 30 | e | 47 | v | (pad) | = |
| 14 | O | 31 | f | 48 | w | ||
| 15 | P | 32 | g | 49 | x | ||
| 16 | Q | 33 | h | 50 | y |
The encoded output stream must be represented in lines of no more
than
76 characters each. All line breaks or other characters not found in
Table
1 must be ignored by decoding software. In base64 data, characters
other
than those in Table 1, line breaks, and other white space probably
indicate
a transmission error, about which a warning message or even a message
rejection
might be appropriate under some circumstances.
Using MIME in RFC 822 Mail header fields (RFC 2047)
Like the encoding techniques described in RFC 2045, the techniques described in RFC 2047 were designed to allow the use of non-ASCII characters in message headers in a way which is unlikely to be distorted by existing Internet mail handling programs. In particular, some mail relaying programs are known to
Certain sequences of "ordinary" printable ASCII characters (known as "encoded-words") are reserved for use as encoded data. The syntax of encoded-words is such that they are unlikely to "accidentally" appear as normal text in message headers. Furthermore, the characters used in encoded-words are restricted to those which do not have special meanings in the context in which the encoded-word appears.delete some message header fields while retaining others, rearrange the order of addresses in To or Cc fields, rearrange the (vertical) order of header fields, and/or "wrap" message headers at different places than those in the original message. In addition, some mail reading programs are known to have difficulties correctly parsing message headers.
Generally, an "encoded-word" is a sequence of printable ASCII characters that begins with "=?", ends with "?=", and has two "?"s in between. It specifies a character set and an encoding method, and also includes the original text encoded as graphic ASCII characters, according to the rules for that encoding method.
A mail composer that implements this specification will provide a means of inputting non-ASCII text in header fields, but will translate these fields (or appropriate portions of these fields) into encoded-words before inserting them into the message header.
A mail reader that implements this specification will recognize encoded-words when they appear in certain portions of the message header. Instead of displaying the encoded-word "as is", it will reverse the encoding and display the original text in the designated character set.
Syntax of encoded-words
An 'encoded-word' is defined by the ABNF notation of RFC 822, with the exception that white space characters MUST NOT appear between components of an 'encoded-word'.
Both 'encoding' and 'charset' names are case-independent. An 'encoded-word' may not be more than 75 characters long, including 'charset', 'encoding', 'encoded-text', and delimiters. If it is desirable to encode more text than will fit in an 'encoded-word' of 75 characters, multiple 'encoded-word's (separated by CRLF SPACE) may be used.encoded-word = "=?" charset "?" encoding "?" encoded-text "?="
The 'charset' portion of an 'encoded-word' specifies the character set associated with the unencoded text. A 'charset' can be any of the character set names allowed in a MIME "charset" parameter of a "text/plain" body part, or any character set name registered with IANA for use with the MIME text/plain content-type.
Initially, the legal values for "encoding" are "Q" and "B". These encodings are described below. The "Q" encoding is recommended for use when most of the characters to be encoded are in the ASCII character set; otherwise, the "B" encoding should be used. Nevertheless, a mail reader which claims to recognize 'encoded-word's MUST be able to accept either encoding for any character set which it supports.
The "B" encoding automatically meets these requirements. The "Q" encoding allows a wide range of printable characters to be used in non-critical locations in the message header (for example, Subject), with fewer characters available for use in other locations.
The "B" encoding is identical to the "BASE64" encoding defined by RFC 2045.
The "Q" encoding is similar to the "Quoted-Printable" content-transfer-encoding defined in RFC 2045. It is designed to allow text containing mostly ASCII characters to be decipherable on an ASCII terminal without decoding.
A mail reader must parse the message and body part headers according to the rules in RFC 822 to correctly recognize 'encoded-word's. Any 'encoded-word's so recognized are decoded, and if possible, the resulting unencoded text is displayed in the original character set.
If the mail reader does not support the character set used, it may
(a) display the 'encoded-word' as ordinary text (i.e., as it appears in the header),A mail reader need not attempt to display the text associated with an 'encoded-word' that is incorrectly formed. However, a mail reader MUST NOT prevent the display or handling of a message because an 'encoded-word' is incorrectly formed.(b) make a "best effort" to display using such characters as are available, or
(c) substitute an appropriate message indicating that the decoded text could not be displayed.
The following are examples of message headers containing 'encoded-word's:
Note: In the first 'encoded-word' of the Subject field above, the last "=" at the end of the 'encoded-text' is necessary because each 'encoded-word' must be self-contained (the "=" character completes a group of 4 base64 characters representing 2 octets). An additional octet could have been encoded in the first 'encoded-word' (so that the encoded-word would contain an exact multiple of 3 encoded octets), except that the second 'encoded-word' uses a different 'charset' than the first one.From: =?US-ASCII?Q?Keith_Moore?=To: =?ISO-8859-1?Q?Keld_J=F8rn_Simonsen?= CC: =?ISO-8859-1?Q?Andr=E9?= Pirard Subject: =?ISO-8859-1?B?SWYgeW91IGNhbiByZWFkIHRoaXMgeW8=?= =?ISO-8859-2?B?dSB1bmRlcnN0YW5kIHRoZSBleGFtcGxlLg==?=
Summary and next development of MIME specificationFrom: =?ISO-8859-1?Q?Olle_J=E4rnefors?=To: ietf-822@dimacs.rutgers.edu, ojarnef@admin.kth.se Subject: Time for ISO 10646? To: Dave Crocker Cc: ietf-822@dimacs.rutgers.edu, paf@comsol.se From: =?ISO-8859-1?Q?Patrik_F=E4ltstr=F6m?= Subject: Re: RFC-HDR care and feeding From: Nathaniel Borenstein (=?iso-8859-8?b?7eXs+SDv4SDp7Oj08A==?=) To: Greg Vaudreuil , Ned Freed
, Keith Moore Subject: Test of new header generator MIME-Version: 1.0 Content-type: text/plain; charset=ISO-8859-1
Using the MIME-Version, Content-Type, and Content-Transfer-Encoding header fields, it is possible to include, in a standardized way, arbitrary types of data with RFC 822 conformant mail messages. No restrictions imposed by either RFC 821 or RFC 822 are violated, and care has been taken to avoid problems caused by additional restrictions imposed by the characteristics of some Internet mail transport mechanisms (see RFC 2049).
RFC 2231 (MIME Parameter Value and Encoded Word Extensions: Character Sets, Languages, and Continuations) [28] defines extensions to the RFC 2045 media type and RFC 2183 [29] disposition parameter value mechanisms to provide
RFC 2231 This memo also defines an extension to the encoded words defined in RFC 2047 to allow the specification of the language to be used for header information displaying together with the character set. This is simply done by suffixing the character set specification with an asterisk followed by the language tag. For example:a means to specify parameter values in character sets other than US-ASCII (as it limited to by MIME specification), to specify the language to be used should the value be displayed, and a continuation mechanism for long parameter values to avoid problems with header line wrapping.
The memo also stressed the impotence of character set facility to inline specification of language what was actually realised in Unicode language tagging (see Unicode section of this report).From: =?US-ASCII*EN?Q?Keith_Moore?=<moore@cs.utk.edu>
Charset names used in MIME in other Internet protocols should be registered according RFC 2278 that defines charsets and its components CCS and CES and lists requirement to the new charsets that could be registered. These requirements include characteristics, naming, usage and implementation, functionality, publication.
IETF Policy in internationalisation and character sets encourage use
of UTF-8 charset in Internet Mail using MIME. UTF-7 use due to of its
limitation
is strongly discouraged.
2.3. IETF Policy on internationalisation and Character Sets
2.3.1. RFC 2277 IETF Policy on Character Sets and Languages
RFC 2277 [27] lists the suggested practices in internationalisation recommended to be used in development of standards that deal with internationalization. It covers topics such as when a protocol must have internationalization, what charsets to use, how to do language tagging, and so on.
International character of Internet demands from Internet protocols, applications and software to have ability to interchange data in a multiplicity of languages, which in turn utilise a bewildering number of characters.
But standard declares that protocols are not subject to internationalization; text strings which are for humans are.
Internet protocols must have the following i18n features regarding charsets used
Many operations, including high quality formatting, text-to-speech synthesis, searching, hyphenation, spellchecking and so on benefit greatly from access to information about the language of a piece of text.
How this is done will vary between protocols; for instance, in some cases, a negotiation where the client proposes a set of languages and the server replies with one is appropriate; in other cases, a server may choose to send multiple variants of a text and let the client pick which one to display.
The POSIX standard defines a concept called a "locale", which includes a lot of information about collating order (for sorting), date format, currency format and so on.
In some cases, and especially with text where the user is expected to do processing on the text, locale information may be usefully attached to the text; this would identify the sender's opinion about appropriate rules to follow when processing the document, which the recipient may choose to agree with or ignore.
RFC 2277 does not require the communication of locale information on all text, but encourages its inclusion when appropriate. Use of locale expected will provide common approach to API and therefore applications themselves internationalisation.
The default locale is the "POSIX" locale.
2.3.4. Recommendation of IAB Workshop on character sets technology (RFC 2130)
RFC 2130 provides an executive summary of IAB Workshop on character sets technology [26].
This workshop provides guidance to the IAB and IETF about the use of character sets on the Internet and provides a common framework for interoperability between the many characters in use there.
The framework consists of four components:
According to strong statement from the IAB, RFC 1958 [33]:
4.3 Public (i.e. widely visible) names should be in case independent ASCII. Specifically, this refers to DNS names, and to protocol elements that are transmitted in text format.Architectural model
...
5.4 Designs should be fully international, with support for localization (adaptation to local character sets). In particular, there should be a uniform approach to character set tagging for information content.
The basic architectural model proposed by workshop is shown in below. A distinction was made between those segments which were necessary to successfully transmit character set data on-the-wire and those needed to present that data to a user in a comprehensible manner. The discussions were primarily restricted to those segments of the model which specify the 'on-the-wire' transmission of textual data.
There are three segments of the model which are required for completely specifying the content of a transmitted text stream (with the occasional exception of the Language component, mentioned above).
Each of these abstract components must be explicitly specified by
the
transmitter when the data is sent. There may be instances of an
implicit
specification due to the protocol/standard being used (i.e. ANSI/NISO
Z39.50).
Also, in MIME, the Coded Character Set and Character Encoding Scheme
are
specified by the Charset parameter to the Content-Type header field,
and
Transfer Encoding Syntax is specified by the Content-Transfer-Encoding
header field.
| User interface issues | ||
| Layout | Layout includes the elements needed for displaying text to the user, such as font selection, word-wrapping, etc. It is similar to the 'presentation' layer in the 7-layer ISO telecommunications model [46]. | |
| Culture | Culture includes information about cultural preferences, which affect spelling, word choice, and so forth. | |
| Locale | The locale component includes the information necessary to make choices about text manipulation which will present the text to the user in an expected format. This information may include the display of date, time and monetary symbol preferences. Notice that locale modifications are typically applied to a text stream before it is presented to the user, although they also are used to specify input formats. | |
| Language | This component specifies the language of the transmitted text. At times and in specific cases, language information may be required to achieve a particular level of quality for the purpose of displaying a text stream. For example, UTF-8 encoded Han may require transmission of a language tag to select the specific glyphs to be displayed at a particular level of quality. | |
| On-the-wire | ||
| The Coded Character | A Coded Character Set (CCS) is a mapping from a set of abstract characters to a set of integers. Examples of coded character sets are ISO 10646 [51], US-ASCII [41], and ISO-8859 series [47]. | |
| The Character Encoding Scheme | A Character Encoding Scheme (CES) is a mapping from a Coded Character Set or several coded character sets to a set of octets. Examples of Character Encoding Schemes are ISO 2022 [42] and UTF-8 [55]. A given CES is typically associated with a single CCS; for example, UTF-8 applies only to ISO 10646. | |
| The Transfer Encoding Syntax | It is frequently necessary to transform encoded text into a format which is transmissible by specific protocols. The Transfer Encoding Syntax (TES) is a transformation applied to character data encoded using a CCS and possibly a CES to allow it to be transmitted. Examples of Transfer Encoding Syntaxes are Base64 Encoding [18], gzip encoding, and so forth. | |
These layers should be specified in a transmitted text stream by
using
the MIME encoding mechanisms.
Recommended Defaults
In mail, text is a predominant data type and coded character sets
then
become a major issue for the protocol. Also, since e-mail is ubiquitous
and users expect to be able to send it to everyone, the mail protocols
need to be quite adept at handling different character set encodings.
Protocols
with a greater need for character set support will need a more
elaborate
specification technique. This task generally can be solved by one of
two
alternative ways: using universal charset, or elaborate sophisticated
mechanism
for handling multiple coded character sets???
| Layer | Defaults | Specification technique |
| Coded Character Set | Repertoire of ISO-10646 | |
| Character Encoding Scheme | UTF-8 (or text-oriented protocols, new protocols)
US-ASCII for mail; ISO-8859-1 for HTTP (for protocols that have a backwards compatibility requirement) |
Recommended specification scheme is the MIME "charset" specification, using the IANA "charset" specifications |
| Transport Encoding Scheme | There is no recommended default for this level.
For plain text oriented protocols, the bytestream transport format should be 8-bit clean, possibly with normalization of end-of-line indicators. |
The specification technique should either be defined in the protocol, if only one way is permitted, or by use of MIME content-transfer-encoding (CTE) techniques, using IANA registered values. |
| Language | (RFC 2277 Recommendation) | The specification technique should be a MIME identifier with IANA registered values for languages. If headers are used, the header should be 'Content-Language'. |
| Locale | The default should be the POSIX locale. | The specification technique should use the Cultural register of CEN ENV 12005 for the values. If headers are used, the header should be 'Content-Locale'. |
| Culture | There is no recommended default for the Culture level. | The specification technique should be a MIME or MIME-like identifier (e.g. Content-Culture) and should use the Cultural register of CEN ENV 12005 for its values. |
| Presentation | There is no recommended default for the Presentation level. | The specification technique should be a MIME or MIME-like identifier (e.g. Content-Layout) and use the glyph register of ISO 10036 and other registers for its values. |
The following table describes how existing protocols dealing with
human
written and readable messages handle multiple character set
information.
| SMTP | ESMTP makes it easy to negotiate the use of alternate language and encoding if it is needed. |
| Headers | RFC 1522 forms an adequate framework for supporting text; UTF-8 alone is not a possible solution, because the mail pathways are assumed to be 7-bit 'forever'. However, RFC 1522 should be extended to allow language tagging of the free text parts of message headers. |
| Bodies | Selection of charset parameters for Email text bodies is reasonably well covered by the charset= parameter on Text/* MIME types. Language is defined by the Content-language header of RFC 1766. Other information will have to be added using body part headers; due to the way MIME differentiates between body part headers and message headers, these will all have to have names starting with Content- . |
| IMAP | IMAP's information objects are MIME Email objects, and therefore are able to use that standard's methods. However, IMAP folder names are local identifiers; there is strong reason to allow non-ASCII characters in these. A UTF-8 negotiation might be the most appropriate thing, however, UTF-8 is awkward to use. Unfortunately, UTF-7 isn't suitable because it conflicts with popular hierarchy delimiters. The most recent IMAP work in progress specification describes a modified UTF-7 which avoids this problem. |
| NetNews | |
| NNTP | No strong tradition for negotiation of encoding in NNTP exists. |
| NetNews Messages | These should be able to leverage off the mechanisms defined for Email. One difference is that nearly all NNTP channels are 8-bit clean; some NNTP newsgroups have a tradition of using 8-bit charsets in both headers and bodies. Defining character set default on a per newsgroup basis might be a suitable approach. |
New protocols do not suffer from the need to be compatible with old 7-bit pipes. New protocol specifications SHOULD use ISO 10646 as the base charset unless there is an overriding need to use a different base character set.
New protocols SHOULD use values from the IANA registries when referring to parameter values. The way these values are carried in the protocols is protocol dependent; if the protocol uses RFC-822-like headers, the header names already in use SHOULD be used.
Protocols SHOULD tag text streams with the language of the text.
Determining which values of CCS, CES, and TES are used in communication
To completely specify which CCS, CES, and TES are used in a specific text transmission, there needs to be a consistent set of labels for specifying which CCS, CES, and TES are used. Once the appropriate mechanisms have been selected, there are six techniques for attaching these labels to the data.
The labels themselves are named and registered, either with IANA [22] or with some other registry. Ideally, their definitions are retrievable from some registration authority.
Labels may be determined in one of the following ways:
2.4. ISO standardsDetermined by guessing, where the receiver of the text has to guess the values of the CCS, CES, and TES. For example: "I got this from Sweden so it's probably ISO-8859-1." This is obviously not a very foolproof way to decode text. Another example widely used is guessing from used or communicating user agents. Determined by the standard, where the protocol used to transmit the data has made documented choices of CCS, CES, and TES in the standard. Thus, the encodings used are known through the access protocol, for example HTTP uses (but is not limited to) ISO-8859-1, SMTP uses US-ASCII. Attached to the transfer envelope, where the descriptive labels are attached to the wrapper placed around the text for transport. MIME headers are a good example of this technique. Included in the data stream, where the data stream itself has been encoded in such a way as to signal the character set used. For example, ISO-2022 encodes the data with escape sequences to provide information on the character subset currently being used. Agreed by prior bilateral agreement, where some out-of-band negotiation has allowed the text transmitter and receiver to determine the CCS, CES, and TES for the transmitted text. Agreed to by negotiation during some phase, typically initialization of the protocol.
ISO standards are industry standards. ISO works as official International standard organisation supported and legalised by participating National Standard Organisations.
ISO developed and introduced a number of industry standards that provide basis for internationalisation of IT, particularly, in Character Set technologies and APIs [37]. The most important are:
General standards
ISO 639 - defines 2-letters names of the languages used (although it also specifies its own extension mechanism)Character Sets technology standards:ISO 639-2 DIS - defines 3-letters of languages (standard draft)
ISO 3166 - defines the names of countries.
ISO/IEC 2022 International Standard -- Information Processing -- Character Code Structure and Extension Techniques, ISO/IEC 2022:1994, 4th ed.ISO policy on i18n and Cultural requirementsISO 8859. International Standard -- Information Processing -- 8-bit Single-Byte Coded Graphic Character Sets - Part 1-11. - defines different Character Sets
ISO 10646
ISO/IEC 9945-2:1993 "Information Technology - Portable Operating System Interface (POSIX) - Part 2: Shell and Utilities"2.4.1. ISO 2022 Character Set Concept and TerminologyISO/IEC 9995 - Keyboard Internationalisation
Basic principles of ISO/IEC 2022
The construction of a character code according to ISO/IEC 2022 is most simply explained by a mechanical analogy [42, 43]. It is like a typewriter that takes interchangeable typeheads ("golfballs"). A typewriter without a typehead can't actually type anything but its mechanisms are all in place. The non-printing keys, such as the space bar and backspace, still operate. It is only the printing characters that are missing.
The typehead itself is an inert object, but once placed on the typewriter then each key on the typewriter will print the character that is at a specific position on the typehead. Change the typehead and the typewriter prints different characters, but the relationship between keys and character positions does not change.
The role of the typewriter is taken in ISO/IEC 2022 by a code table. There is one code table for 7-bit codes and another for 8-bit codes. Each code table provides a linkage between character positions and bit combinations. Certain of these positions are already assigned, for the SPACE, DELETE and ESCAPE characters, but the vast majority of character positions are empty. The table is waiting for its equivalent of a typehead.
The role of the typehead is taken in ISO/IEC 2022 by a code element of graphic characters. Such a code element contains a pattern of graphic characters that can be overlaid on (part of) the empty code table. Once overlaid, it provides a graphic character at each of the overlaid positions. The combination of code table and code element completes (part of) the code; the character at a particular position is coded by the bit combination assigned to that position.
Structure
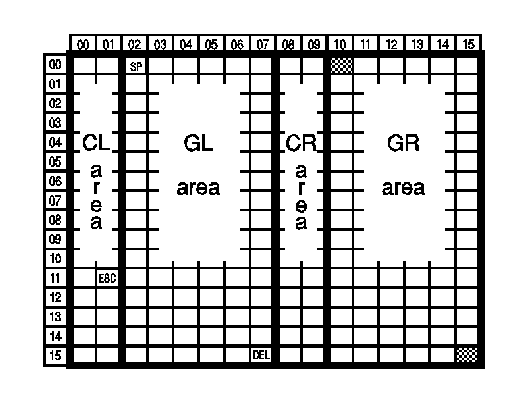
The 8-bit code table is divided into four named areas:
The 7-bit code table is similarly divided, but it only has CL and GL areas. The 8-bit code table is illustrated in this diagram:Columns 00 and 01 are called the CL area; Columns 02 to 07 are called the GL area; Columns 08 and 09 are called the CR area; Columns 10 to 15 are called the GR area.
ISO/IEC 2022 requires that the bit combinations in the CL and CR areas shall be used to represent control functions or be left unused. Only those in the GL and GR areas may be used to represent graphic (printing) characters.The 8-bit code table.
Certain characters have fixed assignments in both the 7-bit and 8-bit code tables as follows:
ISO/IEC 2022 constructs a complete code from a selection of the following code elements:
All of these elements may be present in either a 7-bit or an 8-bit code.Four code elements named G0, G1, G2 and G3 containing graphic characters, arranged as possible overlays for the GL and GR areas of the 8-bit code table; Two code elements named C0 and C1 containing control characters, arranged as possible overlays for the CL and CR areas of the 8-bit code table; A number, possibly zero, of other control functions.
Code elements G0, G1, G2 and G3 of graphic characters
The code elements G1, G2 and G3 may each provide assignments for either 94 or 96 character positions. A set with 94 positions would provide assignments for positions 2/1 to 7/14 of the GL area or 10/1 to 15/14 of the GR area, i.e. excluding the positions assigned to SP and DEL in the GL area and the two corresponding shaded positions in the diagram above for the GR area. A set with 96 positions would provide assignments for all the 96 positions of either the GL or GR area. The code element G0 is similar but only the 94-position option is permitted.
Here is a diagram of a 94-position code element that is suitable for use as any of G0 to G3. It is in fact the ASCII character set:

Code elements C0 and C1 of control charactersA 94-position code element.
Control characters have a name and an identifying acronym, but no graphic representation. Examples of
control characters are BACKSPACE (BS), BELL (BEL), START OF HEADING (SOH), SINGLE-SHIFT 2 (SS2) and ESCAPE (ESC). They are a special case of a more general concept, the control function, as explained above concerning escape sequences.
The code elements C0 and C1 each provide assignments to control characters for the 32 character positions of either the CL or CR area. If the code has a C0 code element then this is permanently invoked in the CL area. A C0 code element is required to have the ESCAPE character in position 01/11 so that its invocation does not affect the availability or coding of this control character.
If an 8-bit code has a C1 code element, it would normally be permanently invoked in the CR area. This is not possible for a 7-bit code since there is no CR area in the code table. Instead, the characters of the C1 code element are represented in a 7-bit code by means of an escape sequence. This representation is also permitted for an 8-bit code, as an alternative to invocation in the CR area. In a particular code, only one of the two alternatives is permitted. The choice should form part of the specification of an 8-bit code.
Repertoire of a code
It is sometimes convenient to be able to refer to the set of characters that can be represented by a code, in a manner abstracted from the details of that representation. This set of characters is known as the repertoire of the code.
The concept of a repertoire is more subtle than it may seem to be at first. Certain character set standards permit two or more characters to be combined in specified ways to create new characters that belong to the repertoire but which are not themselves represented in the code. It is this distinction between representation in, and representation by, a code that causes the subtlety.
Character Sets - Graphic Characters
ISO/IEC 2022 provides for sets of graphic characters to make use of either 94 or 96 code positions. It also prohibits the characters SPACE and DELETE from being assigned in any such set. When these sets are invoked
1. a 94 position set in the GL area provides assignments for bit combinations 02/01 to 7/14;All four possibilities are permitted. When a 96 position set is invoked in the GL area it overlays the positions 02/00 and 07/15 that are otherwise assigned to the SPACE and DELETE characters. The characters SPACE and DELETE are therefore not available in this situation. When a 94 position set is invoked in the GR area, the bit combinations 10/00 and 15/15 shall not be used.
2. a 94 position set in the GR area provides assignments for bit combinations 10/01 to 15/14;
3. a 96 position set in the GL area provides assignments for bit combinations 02/00 to 7/15;
4. a 96 position set in the GR area provides assignments for bit combinations 10/00 to 15/15.
ISO/IEC 2022 permits the G1, G2 and G3 code elements to be sets of either 94 or 96 positions but the G0 set is required to have only 94 positions. It also permits the G1, G2 and G3 code elements to be invoked into either the GL area or the GR area of the code table but the G0 code element is only permitted to be invoked into the GL area. This technique provides basis for constructing "nested" multibyte character sets.
ISO/IEC 2022 provides for two alternative types of allocation to the code positions of a 94 or 96 position set:
1. Each position may either have a character assigned to it or be left unused, orIn the second case a 94 position set may only have its positions allocated to further 94 position sets, and similarly a 96 position set may only have its positions allocated to further 96 position sets. Nesting of sets within sets is permitted to any depth.
2. Each position may either have a further 94 or 96 position set assigned to it or be left unused.
Coding of nested sets
When a nested set is invoked, more than one bit combination (byte) is required to represent an individual character. A sequence of bytes is used that may be processed by the following algorithm:
Take the next byte in the sequence (which initially will be the first byte). It identifies either a character or a character set at the code position referenced by that byte in the currently invoked set. If it identifies a character set, go to step 2. If it identifies a character, go to step 3.The effect of this algorithm is that the characters of a nested set may be represented by a sequence of one or more bytes with the following properties:The identified character set is invoked, for processing the next byte only, into the same area (GL or GR) of the code table as the set currently being processed, therefore replacing it. Processing is then repeated from step 1.
The identified character is the character represented by the byte sequence. Processing is complete.
A character set that is nested in this way is called a multiple-byte set. A set that is not so nested is called a single-byte set.every character of the set is represented by the same number of bytes; every byte of the sequence is in the range appropriate to the status of the set as a 94 or 96 position set invoked into the GL or GR area as described above.
As an illustration of the effect of the coding algorithm, if a character would be represented by the sequence 03/01 05/04 when a particular two-byte set is invoked in the GL area then it would be represented by 11/01 13/04 if the same set were invoked into the GR area.
Chinese, Japanese and Korean national standards
Two-byte coded character sets have been registered in the ISO 2375 Register to permit Japanese, Chinese and Korean ideograph scripts to be coded within the ISO/IEC 2022 code structure. These sets are taken from corresponding national standards. They are in fact very comprehensive character sets that provide multilingual facilities; they are not confined to the ideograph characters of the languages concerned.
Particular examples are as follows:
ISO-IR 87 (ESC 02/04 xx 04/02) : Japanese standard JIS C 6226:1983
This 94-position two-byte set contains 6877 graphic characters that
include 147 symbols, digits 0-9, Latin letters A-Z and a-z, Hiragana,
Katakana,
24 Greek and 33 Cyrillic letters in both capital and small forms,
Japanese
Kanji, and 32 line drawing characters. There remain 1959 unallocated
byte
pairs that shall not be used.
ISO-IR 168 (ESC 02/06 04/00 ESC 02/04 xx 04/02) : Japanese standard
JIS X 0208:1990.
This is a revision of ISO-IR 87 and is designated by the same escape sequences, preceded by the escape sequence that identifies a first revision. The revision introduces two additional characters. More information about the identification of revised registrations is given under escape sequences with intermediate bytes in the section of this guide on control functions.ISO-IR 159 (ESC 02/04 gg 04/04) : Japanese standard JIS X 0212:1990.
This 94-position two-byte set contains 6067 characters that supplement those of ISO-IR 87 or ISO-IR 168. It provides 21 additional symbols, 27 additional Latin letters such as ? and ?, 171 Latin letters with diacritical marks, 21 Greek letters (final sigma and 20 letters with diacritical marks), 26 additional Cyrillic letters and 5801 additional Japanese Kanji characters.ISO-IR 149 (ESC 02/04 gg 04/03) : Korean standard KS C 5601:1987.
This 94-position two-byte set contains 8224 characters that include 276 symbols, digits in both Arabic (0,1,...) and Roman (i,ii,... and I,II,...) forms, the Korean Hangul alphabet, Latin letters A-Z and a-z together with 11 additional capital letters and 16 additional small letters, 24 Greek and 33 Cyrillic letters in both capital and small forms, 68 line drawing characters, Japanese Hiragana and Katakana, 2350 Korean Hangul characters, 4888 Korean Hanja characters, and miscellaneous other characters such as vulgar fractions, superscripts and subscripts.ISO-IR 171 (ESC 02/04 gg 04/07) : Chinese standard CNS 11643:1986, Set 1.
This 94-position two-byte set contains 6085 characters that include 234 symbols, digits in Arabic (0,1,...), Roman (i,ii,... and I,II,...) and Chinese forms, Latin letters A-Z and a-z, 24 Greek letters in both capital and small forms, 42 Mandarin phonetic symbols, 213 Chinese character radicals, 33 control code symbols such as "ESC" and "DEL" each as a single graphic, and 5401 of the most frequently used Chinese characters.ISO-IR 172 (ESC 02/04 gg 04/08) : Chinese standard CNS 11643:1986, Set 2.
This 94-position two-byte set contains 7650 of the less frequently used Chinese characters.In these escape sequences, replacement of "gg" by 02/08, 02/09, 02/10 or 02/11 specifies designation as a G0, G1, G2 or G3 code element respectively. Where "xx" has been used in place of "gg", it denotes anexception to the current coding rules of ISO/IEC 2022 in that this bit combination is absent in the designation as a G0 code element. It is still replaced by 02/09, 02/10 or 02/11 to specify designation as a G1, G2 or G3 code element.
2.4.2. ISO 8859-x Character Sets
ISO 8859 is a standardized series of 8bit character sets for writing
in Western alphabetic languages [47, 48].
It was
designed by the European Computer Manufacturer's Association (ECMA)
and comply to ISO 2022 character sets scheme.
The following is a rough list of the languages/alphabets accommodated into the ISO 8859 series.
ISO-8859-1 - Latin 1
Western Europe and Americas: Afrikaans, Basque, Catalan, Danish, Dutch, English, Faeroese, Finnish, French, Galician, German, Icelandic, Irish, Italian, Norwegian, Portuguese, Spanish and Swedish.ISO-8859-2 Latin 2
Latin-written Slavic and Central European languages: Czech, German, Hungarian, Polish, Romanian, Croatian, Slovak, Slovene.ISO-8859-3 - Latin 3
Esperanto, Galician, Maltese, and Turkish.ISO-8859-4 - Latin 4
Scandinavia/Baltic (mostly covered by 8859-1 also): Estonian, Latvian, and Lithuanian. It is an incomplete predecessor of Latin 6.ISO-8859-5 - Cyrillic
Bulgarian, Byelorussian, Macedonian, Russian, Serbian and Ukrainian.ISO-8859-6 - Arabic
Non-accented Arabic.ISO-8859-7- Modern Greek
Greek.ISO-8859-8 - Hebrew
Non-accented Hebrew.ISO-8859-9 - Latin 5
Same as 8859-1 except for Turkish instead of IcelandicISO-8859-10 - Latin 6
Latin6, for Lappish/Nordic/Eskimo languages: Adds the last Inuit (Greenlandic) and Sami (Lappish) letters that were missing in Latin 4 to cover the entire Nordic area.2.4.3. ISO Standards on APIs i18n and Formal Description of Cultural Contents
Internationalisation APIs (ISO SD N536) [49]
The purpose of ISO SD N536 standard is to specify a set of APIs for internationalization. It contains a functional overview, and a specification of the individual APIs with the interface specification and a semantics specification.
The APIs cover support for multiple coded character sets, including ISO/IEC 10646 support and transformations between coded character sets, functional support for the internationalization data specifiable by ISO/IEC 14652, and string handling.
API - an Application Programming Interface, that describes the interface between the application software and the application platform for the service offered by the specification. The APIs are described in the form of a functional description of a function with its name and parameters and return values.
The "encoding" data type defined in standard holds data necessary to convert to and from an external encoding to the internal string representation. This includes mapping of coded characters to the internal repertoire, how to shift between subencodings such as via ISO 2022 techniques, or representation via symbolic character names identified via introducing sequences, and state information.
NOTE The encoding definition is closely related to the "charset" definition in the Internet MIME specification, POSIX localedef functionality and newer developments for the C and C++ programming languages.
The "locale" data type is a pointer to a record with a number of variables capable of holding information sufficient to service all language-dependent internationalization services. The "locale" data type has provisions to affect groups of functionalities in categories, which are:
LC_COLLATEFormal Description of Cultural Contents (ISO/IEC 14652) [50]
LC_CTYPE
LC_MONETARY
LC_NUMERIC
LC_TIME
LC_MESSAGES
International Standard ISO/IEC 14652 was prepared by Joint Technical Committee ISO/IEC JTC 1., "Information Technology", subcommittee 22, "Programming languages, their environments and system software interfaces".
This International Standard defines a general mechanism to specify cultural conventions, and it defines formats for a number of specific cultural conventions in the areas of character classification and conversion, sorting, number formatting, monetary formatting, date formatting, message display, paper formats, addressing of persons, postal address formatting, telephone number handling, measurement handling.
The Standard uses text from ISO/IEC 9945-2:1993 "Information Technology - Portable Operating System Interface (POSIX) - Part 2: Shell and Utilities", primarily clauses 2.4 and 2.5.
A FDCC-set is the definition of the subset of a user's information technology environment that depends on language and cultural conventions. It is made up from one or more categories. Each category is identified by its name and controls specific aspects of the behavior of components of the system. This standard defines following categories:
Standard Locale Specification
LC_CTYPE Character classification, case conversion and code transformation.Additional FDCC specification
LC_COLLATE Collation order.
LC_TIME Date and time formats.
LC_NUMERIC Numeric, non-monetary formatting.
LC_MONETARY Monetary formatting.
LC_MESSAGES Formats of informative and diagnostic messages and interactive responses.
LC_PAPER Paper formatThe description of FDCC-sets is based on work performed in the UniForum Technical Committee Subcommittee on Internationalisation and on POSIX. Wherever appropriate, keywords were taken from the C Standard or the POSIX-2 standard. The C and POSIX term "locale" have been changed into the term "FDCC-set" from ISO/IEC TR 11017 to align with that specification.
LC_NAME Format of writing personal names
LC_ADDRESS Format of postal addresses
LC_TELEPHONE Format for telephone numbers, and other telephone information
LC_MEASUREMENT Information on measurement system
LC_VERSIONS Versions and status of categories
The LC_CTYPE category primarily is used to define the encoding-independent aspects of a character set, such as character classification. In addition, certain encoding-dependent characteristics are also defined for an application via the LC_CTYPE category. This standard does not mandate that the encoding used in the FDCC-set is the same as the one used by the application, because an application may decide that it is advantageous to define FDCC-set in a system-wide encoding rather than having multiple, logically identical FDCC-sets in different encodings, and to convert from the application encoding to the system-wide encoding on usage. Other applications could require encoding-dependent FDCC-sets.
The character set description text provides the capability to describe character set attributes (such as collation order or character classes) independent of character set encoding, and using only the characters in the portable character set. This makes it possible to create "generic" FDCC-set source texts for all code sets that share the portable character set (such as the ISO/IEC 8859 family). Applications are free to describe more than one code set in a character set description text.
The charmap was introduced to resolve problems with the portability of, especially, FDCC-set sources. The charmap allows specification of more than one encoding of a character.
The repertoiremap was introduced to make FDCC-sets independent of the availability of charmaps. With the repertoiremap it is possible to use a FDCC-set encoded with one set of symbolic character names, together with charmaps with other symbolic character naming schemes, provided there are repertoiremaps available for both naming schemes. Repertoiremaps are also useful to describe repertoires of characters, to be used for example for transliteration.
ISO and the Unicode Consortium [54] have developed a Universal Character Set covering all characters from all living languages (and many defunct and artificial languages as well). This character set is specified in ISO/IEC 10646 and in the Unicode Standard [55]. However, the Unicode Standard gives further development of ISO/IEC 10646 and provided semantics to the characters, categorizes them, has many useful rules for handling them, and imposes tighter compliance requirements to guarantee the same behavior on different platforms.
As mentioned earlier, current IETF practice for protocols is to use the UTF-8 charset, which maps to the characters in the Unicode Standard and ISO 10646. UTF-8 defined in the Unicode Standard and ISO/IEC 10646 and described in RFC 2279 [58] for use in Internet protocols (RFC has free distribution in contrary to ISO and Unicode standards distribution for charge).
Unicode Standard also defines the UTF-7 [57] transformation scheme (charset), which was intended for Internet mail. But its limitation to Internet Mail motivated discouraging its use. MIME is quite capable of carrying UTF-8, and UTF-8 is meet requirements to be used in many protocols, not just Internet mail.
Last Unicode Consortium report has defined a way to label the language of text that is encoded in the Unicode Standard - Unicode Technical Report #7: Plane 14 Characters for Language Tags. These tags can be used to switch languages within a single block of text; this differs from the MIME tagging defined in RFC 1766, which defines a single language for an entire body part. This kind of embedded tagging is most useful for multi-language text encoded with UTF-8.
Most of users without technical IT background treat all problems with ML support in SW and MUAs as problem of support given language. But really problems consist of splits support of given language in OS and correct MUA configuring that in its turn need that MUA understand language/charset information. But mainly it’s a problem with character sets (charsets) and font in OS.
1. Developing International Software For Windows 95 and Windows NT, by Nadine Kano, 1995, published by Microsoft Press (ISBN 1-55615-840-8).
2. The ISO 8859 Character Sets. - http://park.kiev.ua/multiling/ml-docs/iso-8859.html
3. Character Set Recognition. - http://www.microsoft.com/msdn/sdk/inetsdk/help/dhtml/references/charsets/charset4.htm
4. Charsets counts by the Babel team's study, 1997. - http://www.w3.org/International/O-charset-lang.html
5. TERENA WG-i18n. - http://www.terena.nl/working-groups/wg-i18n/
6. TERENA WG-MSG. - http://www.terena.nl/working-groups/wg-msg/
7. Information Society Standardization System. - http://www.cenorm.be/isss/
8. CEN/TC 304. Information and Communication Technologies - European Localization Requirements. - http://www.stri.is/TC304/PT.html
9. European Electronic Messaging Association. - http://www.eema.org/
10. Internet Mail Consortium. - http://www.imc.org
11. Using International Characters in Internet Mail. Internet Mail Consortium Report: MAIL-I18. IMCR-010, August 1, 1998. - http://www.imc.org/mail-i18n.html
12. Multilingual Application Interface for Telematic Services. - http://wwwold.dkuug.dk/maits/fact
13. Multilingual Mail Users Agents. TERENA Pilot Project Homepage. - http://park.kiev.ua/multiling/ml-mua/
14. Testing multilingual support in Mail User Agents. TERENA Technical report. - http://www.terena.nl/libr/tech/mlmua-fr.html
15. Postel, J., "Simple Mail Transfer Protocol", STD 10, RFC 821, August, 1982. - ftp://ftp.isi.edu/in-notes/rfc821.txt
16. David H. Crocker, Standard for the Format of ARPA Internet Text Messages, RFC 822, August, 1982. - ftp://ftp.isi.edu/in-notes/rfc822.txt
17. J. Palme, Common Internet Message Headers, RFC 2076, February 1997. - ftp://ftp.isi.edu/in-notes/rfc2076.txt
18. Freed, N., and N. Borenstein, "Multipurpose Internet Mail Extensions (MIME) Part One: Format of Internet Message Bodies", RFC 2045, November 1996. - ftp://ftp.isi.edu/in-notes/rfc2045.txt
19. Freed, N., and N. Borenstein, "Multipurpose Internet Mail Extensions (MIME) Part Two: Media Types", RFC 2046, November 1996. - ftp://ftp.isi.edu/in-notes/rfc2046.txt
20. Moore, K., "Multipurpose Internet Mail Extensions (MIME) Part Three: Representation of Non-Ascii Text in Internet Message Headers", RFC 2047, November 1996. - ftp://ftp.isi.edu/in-notes/rfc2047.txt
21. N. Freed, J. Klensin, J. Postel, MIME Part 4: Registration Procedures, RFC 2048, November 1996. - ftp://ftp.isi.edu/in-notes/rfc2048.txt
22. Freed, N., and N. Borenstein, MIME Part 5: Conformance Criteria and Examples, RFC 2049, November 1996. - ftp://ftp.isi.edu/in-notes/rfc2049.txt
23. S. Nelson, C. Parks, The Model Primary Content Type for Multipurpose Internet Mail Extensions, RFC 2077, January 1997. - ftp://ftp.isi.edu/in-notes/rfc2077.txt
24. E. Levinson, MIME Multipart/Related Content-type, RFC 2387, August 1998. - ftp://ftp.isi.edu/in-notes/rfc2387.txt
25. L. Masinter, Returning Values from Forms: multipart/form-data, RFC 2388, August 1998. - ftp://ftp.isi.edu/in-notes/rfc2388.txt
26. Weider, C., Preston, C., Simonsen, K., Alvestrand, H., Atkinson, R., Crispin, M., and P. Svanberg, "Report from the IAB Character Set Workshop", RFC 2130, April 1997. - ftp://ftp.isi.edu/in-notes/rfc2130.txt
27. H. Alvestrand, IETF Policy on Character Sets and Languages, RFC 2277, January 1998. - ftp://ftp.isi.edu/in-notes/rfc2277.txt
28. N. Freed K. Moore MIME Parameter Value and Encoded Word Extensions: Character Sets, Languages, and Continuations RFC 2231 November 1997. - ftp://ftp.isi.edu/in-notes/rfc2231.txt
29. R. Troost, S. Dorner, K. Moore, Communicating Presentation Information in Internet Messages: The Content-Disposition Header Field, RFC 2183, August 1997. - ftp://ftp.isi.edu/in-notes/rfc2183.txt
30. Simonsen, K., "Character Mnemonics & Character Sets", RFC 1345, Rationel Alim Planlaegning, June 1992. - ftp://ftp.isi.edu/in-notes/rfc1345.txt
31. Alvestrand, H., "X.400 Use of Extended Character Sets", RFC 1502, SINTEF DELAB, August 1993. - ftp://ftp.isi.edu/in-notes/rfc1502.txt
32. Alvestrad, H., "Tags for the Identification of Languages", RFC 1766, UNINETT, March 1995. - ftp://ftp.isi.edu/in-notes/rfc1766.txt
33. Carpenter, B. (ed.) "Architectural Principles of the Internet", RFC 1958, IAB, June 1996. - ftp://ftp.isi.edu/in-notes/rfc1958.txt
34. Yergeau, F., et.al., "Internationalization of the Hypertext Markup Language", RFC 2070, January 1997. - ftp://ftp.isi.edu/in-notes/rfc2070.txt
35. Chernov, A., "Registration of a Cyrillic Character Set", RFC 1489, RELCOM Development Team, July 1993. - ftp://ftp.isi.edu/in-notes/rfc1489.txt
36. Ukrainian Character Set KOI8-U, RFC 2319, KOI8-U Working Group, April 1998. - ftp://ftp.isi.edu/in-notes/rfc2319.txt
37. International Standard Organisation. 35.040 Character sets and information coding. - http://www.iso.ch/cate/35040.html
38. Guide to Open Systems Specifications. Character Sets. - http://www.ewos.be/tg-cs/gtop.htm
39. ISO 639, "Code for the representation of names of languages"
40. ISO 646, "Information technology - ISO 7-bit coded character set for information interchange"
41. ANSI X3.4:1986 "Coded Character Sets - 7 Bit American National Standard Code for Information Interchange (7-bit ASCII)"
42. ISO/IEC 2022:1994, "Information technology -- Character Code Structure and Extension Techniques", JTC1/SC2.
43. Guide to Open Systems Specifications. Character Sets. Index to Standards - ISO/IEC 2022. - http://www.ewos.be/tg-cs/gis2022.htm
44. ISO/IEC 8824, "Information technology - Open Systems Interconnection - Specification of Abstract Syntax Notation One (ASN.1)"
45. ISO/IEC 8825, "Information technology - Open System Interconnection - Specification of Basic Encoding Rules for Abstract Syntax Notation One (ASN.1)"
46. ISO/IEC 7498-1:1994, "Information technology - Open Systems Interconnection - Basic Reference Model: The Basic Model".
47. Information Processing -- 8-bit Single-Byte Coded Graphic Character Sets -- Part 1: Latin Alphabet no. 1, ISO 8859-1:1987(E). Part 2: Latin Alphabet no. 2, ISO 8859-2: 1987(E). Part 3: Latin Alphabet no. 3, ISO 8859-3:1988(E). Part 4: Latin Alphabet no. 4, ISO 8859-4, 1988(E). Part 5: Latin/Cyrillic Alphabet ISO 8859-5, 1988(E). Part 6: Latin/Arabic Alphabet, ISO 8859-6, 1987(E). Part 7: Latin/Greek Alphabet, ISO 8859-7, 1987(E). Part 8: Latin/Hebrew Alphabet, ISO 8859-8-1988(E).Part 9: Latin Alphabet no. 5, ISO 8859-9, 1990(E). Part 10: Latin Alphabet no. 6, ISO 8859-10:1992(E).
48.Roman Czyborra, ISO 8859 Alphabet Soup. - http://czyborra.com/charsets/iso8859.html
49. Information Technology — Internationalization APIs. ISO/IEC JTC1/SC22/WG20 N536. - http://osiris.dkuug.dk/JTC1/SC22/WG20/docs/n536.htm
50. Cultural convention specification standard
(future
ISO/IEC 14652). - http://osiris.dkuug.dk/JTC1/SC22/WG20/docs/14652fcd.txt
51.ISO/IEC 10646-1:1993(E ), "Information technology - Universal Multiple-Octet Coded Character Set (UCS) -- Part 1: Architecture and Basic Multilingual Plane". JTC1/SC2, 1993
52.Institute of Electrical and Electronics Engineers. "IEEE standard interpretations for IEEE standard portable operating systems interface for computer environments". IEEE Std 1003.1 - 1988/Int, 1992 edition. Sponsor, Technical Committee on Operating Systems of the IEEE Computer Society. New York, NY: Institute of Electrical and Electronic Engineers, 1992.
53. "The Unicode standard, version 2.0. Unicode Consortium. Reading, Mass.: Addison-Wesley Developers Press, 1996
54. Unicode Consortium. - http://www.unicode.org
55. International Standards Organization, Joint Technical Committee 1 (ISO/JTC1), "Amendment 2:1993, UCS Transformation Format 8 (UTF-8)", in ISO/IEC 10646-1:1993 Information technology - Universal Multiple-Octet Coded Character Set (UCS) -- Part 1: Architecture and Basic Multilingual Plane. JTC1/SC2, 1993.
56. Goldsmith, D., and M. Davis, "Using Unicode with MIME", RFC 1641, Taligent, Inc., July 1994. - ftp://ftp.isi.edu/in-notes/rfc1641.txt
57. Goldsmith, D., and M. Davis, A Mail-Safe Transformation Format of Unicode (UTF-7), RFC 2152, May 1997. - ftp://ftp.isi.edu/in-notes/rfc2152.txt
58. F. Yergeau UTF-8, a Transformation Format
of Unicode and ISO 10646, RFC 2279, January 1998. - ftp://ftp.isi.edu/in-notes/rfc2279.txt