ISO 8859 is a standardized series of 8bit character sets for writing in Western alphabetic languages. It was designed by the European Computer Manufacturer's Association (ECMA).
The following is a rough list of the languages accomodated in the ISO 8859 series.
Shortcomings of the ISO 8859 series
The ISO 8859 series lacks the ligatures Dutch ij, French oe and ,,German`` quotation marks, as well as several other characters. There are also Bulgarian and Ukranian characters missing from ISO 8859-5.
A description of most of these character sets and correspondent charsets (or encoding) can be found in RFC 1345 and Cultural Registry maintained by Keld Simonsen.
The following bitmap GIFs show only the upper part of the respective character sets with number from 160 to 255. Characters 0 to 127 are always compliant with US-ASCII and the positions 128 to 159 hold control characters nobody ever uses.
ISO/IEC 2022 Character Sets Concepts and terminology see at http://www.ewos.be/tg-cs/gconcept.htm
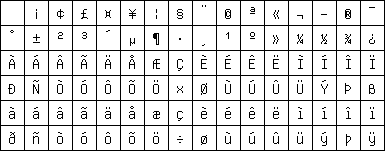
Latin 1 covers most West European languages such as Albanian, Catalan, Danish, Dutch, English, Faeroese, Finnish, French, German, Galician, Irish, Icelandic, Italian, Norwegian, Portuguese, Spanish, and Swedish. The lack of the ligatures Dutch ij, French oe and ,,German`` quotation marks is tolerable.

Latin 2 is used for most Latin-written Slavic and Central European languages: Czech, German, Hungarian, Polish, Rumanian, Croatian, Slovak, Slovene.

Latin 3 is popular with authors of Esperanto, Galician, Maltese, and Turkish.

Latin 4 introduces letters for Estonian, Latvian, and Lithuanian. It is an incomplete predecessor of Latin 6.

This page is used for Bulgarian, Byelorussian, Macedonian, Russian, Serbian and Ukrainian. This Charset lack of Ukrainian letter GHE WITH UPTURN.
There are KOI8-R encoding of Russian Alphabet and KOI8-U encoding for Ukrainian Alphabet which are widely used for Internet mail system and other Internet information.

Each Arabic letter occurs in four easily predictable forms: initial, medial, final or separate. To make Arabic text legible you'll need a display engine that combines the appropriate glyphs. The fixed font is not an acceptable rendering.

This is Modern Greek.

And this is Hebrew. Like Arabic it is written from the right to the left.
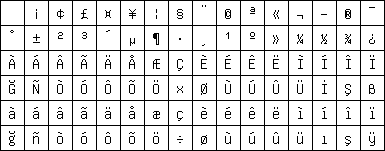
Latin 5 replaces the rarely needed Icelandic letters in Latin 1 with the Turkish ones.

Latin 6 adds extra Inuit (Greenlandic) and Sami (Lappish) letters that were missing in Latin 4 and Latin 6 to cover the entire Nordic area.